



1. Importing the necessary libraries:
import pandas as pd
import re
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import CountVectorizer
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from tensorflow import keras
import matplotlib.pyplot as plt
Here, the code imports the necessary libraries for reading the dataset, preprocessing the data, training and evaluating the model, and plotting the results.
2. Reading the dataset:
train = pd.read_csv('/kaggle/input/22fall-micro-course-4-w2v-d2v/train.csv')
test = pd.read_csv('/kaggle/input/22fall-micro-course-4-w2v-d2v/test.csv')
The code reads the train and test datasets using the pandas library and stores them in the variables 'train' and 'test'.
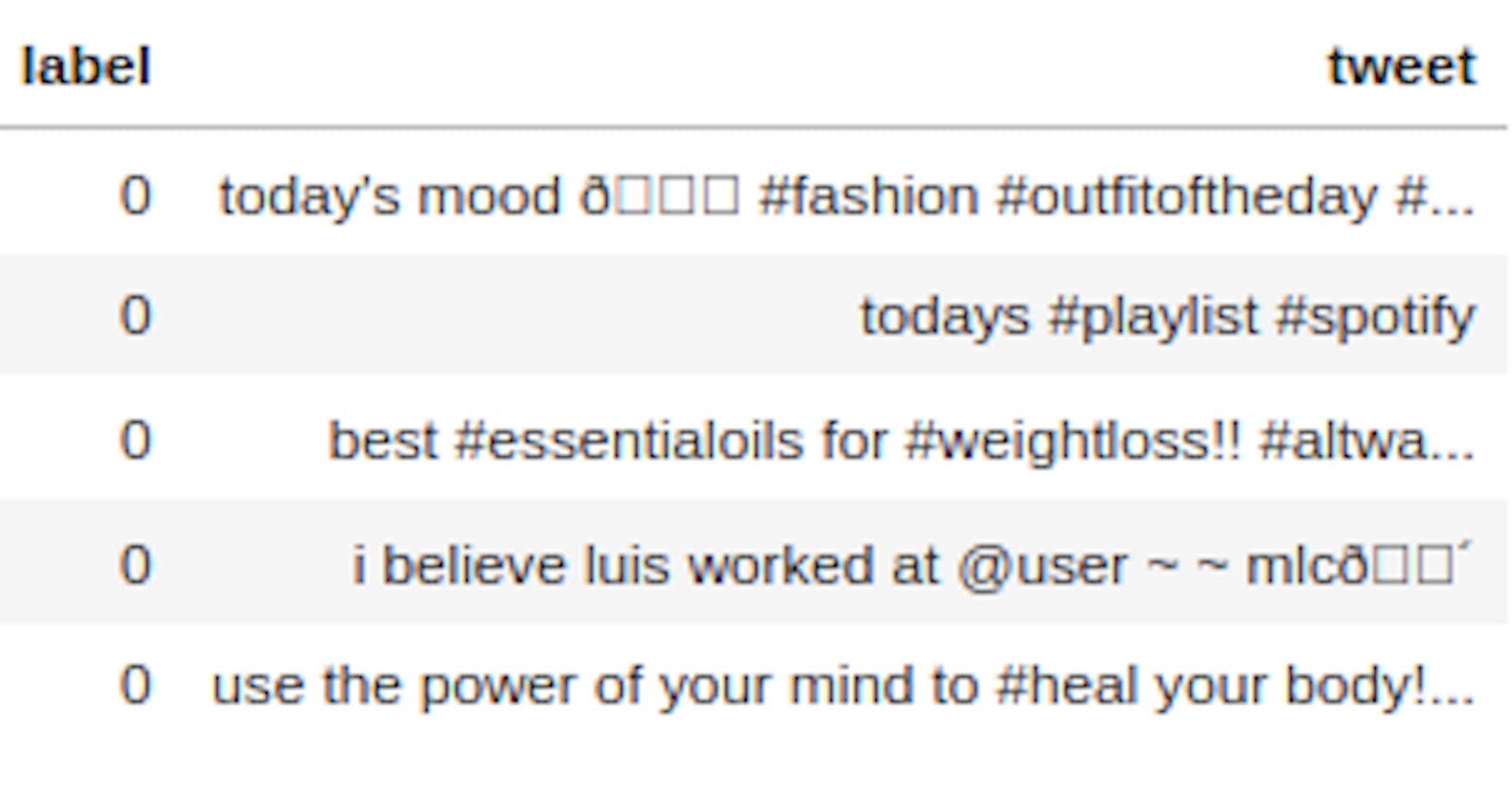
train.head()
| id | label | tweet | |
| 0 | 19813 | 0 | today's mood ð #fashion #outfitoftheday #... |
| 1 | 15607 | 0 | todays #playlist #spotify |
| 2 | 14069 | 0 | best #essentialoils for #weightloss!! #altwa... |
| 3 | 19118 | 0 | i believe luis worked at @user ~ ~ mlcð´ |
| 4 | 12890 | 0 | use the power of your mind to #heal your body!... |
3. Preprocessing the data:
import re
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
def clean_tweet(tweet):
# Remove HTML tags and special characters
tweet = re.sub(r'<.*?>|&[a-z]+;', '', tweet)
# Remove URLs and hashtags
tweet = re.sub(r'https?://\S+|#\S+', '', tweet)
# Tokenize the text
tokens = nltk.word_tokenize(tweet)
# Remove stop words and words that are not in the desired language
tokens = [token for token in tokens if token.lower() not in stopwords.words('english')]
# Remove special characters and punctuation
tokens = [re.sub(r'[^\w\s]', '', token) for token in tokens]
# Convert words to lowercase
tokens = [token.lower() for token in tokens]
tokens = [token for token in tokens if len(token)>1]
return ' '.join(tokens)
# # Example usage
# tweet = "I had a terrible experience at the restaurant last night. The service was slow and the food was overcooked."
# clean_tweet(tweet)
# Output: ['terrible', 'experience', 'restaurant', 'last', 'night', 'service', 'slow', 'food', 'overcooked']
[nltk_data] Downloading package stopwords to /usr/share/nltk_data... [nltk_data] Package stopwords is already up-to-date!
The 'clean_tweet' function is used to preprocess the data. It removes HTML tags, special characters, URLs, hashtags and stop words. The preprocessed tweets are then stored back in the 'train' dataset using the 'apply' function.
4. Converting the tweets to a matrix of token counts:
The vectorizer object from CountVectorizer is used to convert the list of tweets into a matrix of token counts. A token count is a way of representing the frequency of each word in the tweet. The vectorizer object is fit using the fit_transform method, which performs two operations at once: it fits the vectorizer to the data, and then transforms the data into the token count matrix. The result is stored in a variable called X.
# Create a list of the tweets
tweets = train['tweet'].tolist()
# Create a list of the labels
labels = train['label'].tolist()
# Convert the tweets to a matrix of token counts
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(tweets)
5. Split the data into training and testing sets:
To evaluate the accuracy of the model, we need to split the data into training and testing sets. This is done using the train_test_split function from the sklearn.model_selection module. The train_test_split function takes four arguments: the features, the labels, the size of the test set, and the random state (which is used to ensure that the same split is produced every time the code is run). The result of train_test_split is four variables: X_train, X_test, y_train, and y_test. X_train and y_train are the features and labels for the training set, and X_test and y_test are the features and labels for the testing set.
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2)
6. Train the model:
A Multinomial Naive Bayes model is created and fit to the training data using the fit method. The model is stored in a variable called model.
model = MultinomialNB()
model.fit(X_train, y_train)
MultinomialNB()
7. Evaluate the model:
The accuracy of the model is evaluated using the score method on the model object and passing in the testing data. The accuracy is stored in a variable called accuracy and printed to the console.
accuracy = model.score(X_test, y_test)
print("Accuracy:", accuracy)
Accuracy: 0.9382874775006428